Un langage est rarement une couvre d'art. Il est généralement imparfait et évolue en fonction des besoins à satisfaire.
Exemples de langages simples :
Les meilleurs langages, c'est à dire ceux qui sont le plus utilisés, ne sont pas des constructions de savants. Ils ont plutôt été "inventée" par ceux qui en avaient besoin. Les grammairiens, philologues et autres spécialistes en font, après coup, la théorie en s'efforçant d'y trouver logique et beauté.
Des tentatives d'origine extérieure d'introduction d'un langage à vocation universelle se soldent généralement par des échecs, tel celui de 1'esperanto", dont le succès modeste, n'a pas répondu aux espérances de son inventeur, le Professeur ZAMENHOF.
On observe que les langages ne s'imposent pas parce qu'ils sont intrinsèquement les meilleurs, mais parce qu'ils bénéficient d'un véhicule culturel ou économique. L'exemple du français en Alsace ou du russe dans le bloc soviétique montre qu'il est très difficile d'imposer par la contrainte une langue à une population.
Le développement récent de l'humanité a conduit à une extraordinaire prolifération de langages spécialisés destinés à satisfaire des besoins précis de communication, par exemple :
Exemples :
L'exemple le plus typique est peut être celui du téléphone international. Les opératrices utilisées doivent être multilingues et effectuent un travail harassant, qui devrait apparemment pouvoir être aisément effectué par une machine puisque l'abonné appelant est capable de définir sans ambiguïté l'abonné qu'il demande au moyen d'une série plus ou moins longue de chiffres décimaux correspondant à un numéro précédé de tous les préfixes nécessaires.
En réalité, l'automatisation s'est révélée très difficile, car les différents pays (et souvent même les différentes régions d'un même pays) utilisaient des matériels différente que leurs constructeurs respectifs semblaient s'être ingéniés à rendre incompatibles. Deux solutions se présentaient :
C'est bien sûr la seconde solution qui a prévalu, car la première voie, intellectuellement plus séduisante, relève de l'utopie mondialiste : résoudra-t-on un jour les disparités d'écartement ferroviaire ou la conduite automobile à gauche ?
Le développement des ordinateurs au cours des années 60 a fait naître l'espoir qu'ils seraient en mesure de traduire automatiquement les langues humaines les unes dans les autres.
Grammairiens et informaticiens se sont groupés pour résoudre ce problème et ont commencé par améliorer considérablement les théories existantes en matière linguistique. Des formalisations ont été inventées pour décrire les lois de la grammaire, rebaptisée syntaxe.
Donnons quelques exemples de lois grammaticales :
<phrase> ::= <groupe sujet> <groupe verbe> | <phrase> <groupe complément> <groupe nominal> ::= <nom > | <groupe nominal> <adjectif > | <adjectif> <groupe nomina1>
L'idée directrice était que si une machine est capable de reconnaître la structure syntaxique d'une langue donnée, il devient possible de traduire individuellement chaque mot qui compose une phrase d'une langue source et, d'obtenir la traduction globale de cette phrase dans une langue objet, dont les règles syntaxiques seraient respectées. On pouvait même espérer définir une nouvelle langue, qui aurait fait fonction de plaque tournante entre toutes les langues existantes.
L'enthousiasme des pionniers rencontra bien des difficultés. En travaillant sur des textes réels, on découvre que nos langues humaines sont imparfaites et comportent de nombreuses ambiguïtés, et qu'il s'y glisse parfois quelques fautes d'orthographe ou de syntaxe dont l'homme se joue, mais pas les machines.
On obtint des traductions curieuses de phrases telles que celles-ci :
Après de grands progrès dans les connaissances théoriques relatives à la syntaxe et la sémantique, les savants sont parvenus à deux résultats un peu paradoxaux :
Chaque machine un peu compliquée est livrée avec un mode d'emploi, plus ou moins clair, rédigé le plus souvent en plusieurs langues, et le malheureux utilisateur a été contraint de consacrer un temps de plus en plus long à cet apprentissage sans toujours parvenir à maîtriser convenablement les objets mis à sa disposition.
Les fabricants les plus lucides ont réagi en standardisant et en simplifiant au maximum : grille de vitesses normalisées (ou botte de vitesses automatique), machines "presse-bouton".
Dicter ses volontés à une machine est en principe relativement facile lorsqu'on en est l'auteur et que la machine n'est pas trop complexe. A l'inverse, mettre les ordinateurs à la disposition du "grand public" constitue désormais une gageure essentielle à résoudre d'ici à la fin de ce siècle.
La clé réside dans la définition, la découverte et la mise au point de langages adaptés. Ne nous faisons pas d'illusions : le tri s'effectuera de lui-même, au mépris des raisonnements trop théoriques.
La solution la plus simple qui vient à l'esprit pour échanger des informations avec une telle machine consiste à parler avec des zéros et des une :
Il faut regrouper ces chiffres binaires pour les manipuler plus aisément : les chiffres décimaux (base 10) ou hexadécimaux (base 16) constituent déjà un grand progrès. L'adjonction de caractères alphabétiques et de symboles divers de ponctuation permet de disposer, dans les machines à octets d'un potentiel de 256 signes différents beaucoup plus agréable pour les communications avec l'homme puisqu'il permet d'échanger avec la machine aussi bien des nombres que du texte. La généralisation de codes tels que ASCII et EBCDIC constitue un progrès qui permet d'utiliser ces mêmes conventions pour les échanges entre machines différentes.
Ces instructions élémentaires sont relativement peu nombreuses, mais sont déterminées une fois pour toutes lors de la construction de la machine en vue de pouvoir, par des combinaisons plus ou moins compliquées entre elles, reconstituer les séquences plus complexes que lion désire faire réaliser par la machine. Parmi les instructions élémentaires, on distinguera généralement :
| a) les instructions arithmétiques logiques | addition, soustraction, intersection et union logique négation, décalages, . .. |
| b) les instructions de saut |
inconditionnel conditionnel |
| c) instructions d'échange avec la mémoire |
chargement (depuis la mémoire) rangement (vers la mémoire) entrées-sorties |
A chacune de ces instructions correspond un code, dont il convient, si l'on veut définir un programme en langage machine, de connaître la formule en notation binaire, et qui est généralement suivi de un ou plusieurs opérandes (désignation de registres, de drapeaux, ou d'adresses de mémoire) exprimée dans la même notation.
Nous n'insisterons pas sur l'extrême pénibilité du travail d'élaboration et de mise au point de programmes en langage machine (ou langage binaire) qui a conduit ai l'abandonner a peu près systématiquement au profit de langages plus évolués.
ADD : pour une addition JP : pour un saut LD : pour un chargement depuis la mémoire |
De la même manière, on peut décrire les opérandes qui suivent ces codes d'instruction par des notations symboliques littérales analogues à celles qu'utilisent les mathématiciens.
LD X : signifie que l'on désire changer le contenu de la mémoire dont l'adresse X est définie par ailleurs JP LAB : signifie que l'on désire poursuivre l'exécution en un autre point du programme repéré par l'adresse LAB, que l'on appelle alors une étiquette. |
Il n'existe pas a priori de limite au symbolisme que l'utilisateur peut inventer pour décrire les opérations qu'il désire voir exécuter pour une machine donnée. Les règles de ce symbolisme, lorsqu'il reste en correspondance directe avec les instructions élémentaires de la machine, définissent ce qu'on appelle un langage d'assemblage, dont le principal avantage est d'être une traduction du langage machine, plus lisible par l'homme que ce dernier.
La vraie difficulté apparaît évidemment lorsque l'on désire traduire automatiquement le programme exprimé en langage symbolique, qui devient le programme source en un programme directement exprimé en langage binaire, que l'on appelle programme objet.
Les outils de traduction, que l'on appelle des assembleurs sont eux-mêmes des programmes, complexes, qui ne peuvent fonctionner que sur des machines relativement importantes, puisqu'ils doivent :
Le programme objet, encore appelé code objet, est souvent produit par l'assembleur sous forme de module-objet, sur un support permanent tel que :
L'introduction des modules-objet dans l'ordinateur sur lequel il doit être exécuté, et qui peut être différent (surtout pour les petites machines) de celui sur lequel il a été produit, s'effectue par l'intermédiaire d'un chargeur qui est lui-même un petit programme destiné à la lecture et à l'"installation" du module-objet en mémoire.
Des raffinements divers ont été mis au point pour faciliter l'assemblage et l'articulation des modules-objet.
L'utilisation d'un langage d'assemblage n'apporte toutefois qu'un progrès relatif par rapport au langage binaire. La réalisation d'un tel logiciel est souvent l'aboutissement d'une longue et pénible affaire entre un homme, spécialiste, et une machine, particulière, et ne survit pas au départ du premier ou à l'obsolescence technique de la seconde. En d'autres termes, les langages d'assemblages ne prêtent mal à une communication entre machines différentes et entre programmeurs différents. C'est ce qui a justifié l'élaboration des langages dits "évolués".
Grâce à FORTRAN, il devenait possible de programmer plus facilement en équipe, et de transférer les programmes d'une machine sur la suivante (compatibilité vers le haut).
Pour rendre un programme exécutable par la machine, il est évidemment nécessaire de traduire le programme écrit en FORTRAN en langage machine. Cette opération est réalisée par un compilateur, programme particulièrement complexe dont la fourniture accompagnait celle des machines, en même temps que des applications à caractère général pouvaient faire 1'objet, après avoir été rédigées en FORTRAN, d'une large diffusion auprès des différents utilisateurs.
L.S.E., PASCAL, A.P.L. ou A.D.A. réussiront-ils à s'imposer, le premier grâce à la protection des pouvoirs publics en France, les autres par leurs qualités propres ? Au lieu de tenter de répondre à cette question, nous suggérons de prendre en compte la remarque suivante tous ces langages ont en fait des points communs, tels qu'une syntaxe exigeante, une structure proche de la pensée mathématique, une incapacité de s'adapter aux petites erreurs ou maladresses des utilisateurs. Aux yeux du plus grand nombre de non concitoyens, auxquels nous essaierions de présenter le célèbre clavier QWERTY ou AZERTY, ils ont le trait commun de ne pas être véritablement commodes à utiliser. Dès lors, le progrès pourrait venir d'ailleurs, comme de l'ordinateur ATARI, qui ne parle aucun langage informatique, puisqu'on l'actionne avec de petites manettes aussi simples que pour une automobile, qui s'est déguisé en jeu pour investir non foyers, et avec lequel nos enfants, eux, auront vite appris à dialoguer !
Premier paradoxe : la machine calcule extrêmement vite et dispose d'une quantité énorme de mémoire, mais elle ne sait exécuter qu'un petit nombre d'opérations simples que l'on va devoir combiner.
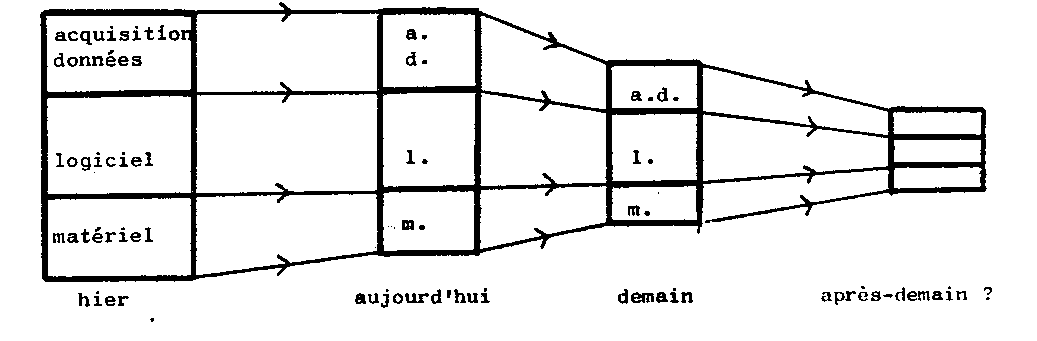
Le travail de programmation, ou d'élaboration du logiciel, reste une activité noble, dont le coût devient actuellement souvent prédominant. En effet, pour une application type donnée, la répartition du prix de revient entre matériel, logiciel et acquisition de données évolue sensiblement comme suit :
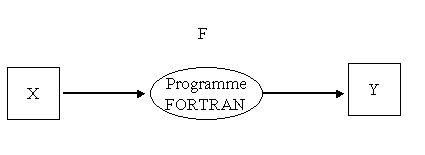
En variant les données, on obtient des résultats différents :
Y1 = F(X1), Y2 = F(X2), ...
Dans le cas d'une simulation de phénomène physique sur ordinateur, par exemple, le programmeur variera les données Xi jusqu'à obtenir un résultat Yi vraisemblable. Il estimera alors les données Xi satisfaisantes (le programme, lui, l'est par définition) et se sentira conforté par l'ordinateur dans ses conclusions concernant Yi.
L'utilisation des ordinateurs en mode conversationnel obéit à un schéma beaucoup plus riche, puisque le résultat du programme dépend aussi des interventions que l'utilisateur peut décider en cours d'exécution. Dans le cas par exemple d'un jeu sur ordinateur, le schéma s'apparente à celui d'une conversation :
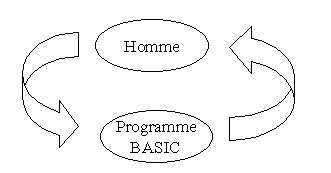
La relation entre l'homme et la machine tend à devenir symétrique, sans l'être tout à fait, puisque la machine ne petit en principe agir sur l'homme qu'en lui donnant des informations (visuelles, sonores ou en différé sur papier ou support magnétique) alors que l'homme peut agir beaucoup plus directement (en débranchant la prise du courant par exemple). Ce schéma d'une simple conversation ne doit pas faire illusion : il est radicalement différent du schéma précédent, car pendant la conversation, l'homme peut interagir avec d'autres hommes, la machine avec d'autres machines, et vice versa, dans le cadre plus général d'une société où hommes et machines, en temps réel, cohabitent.
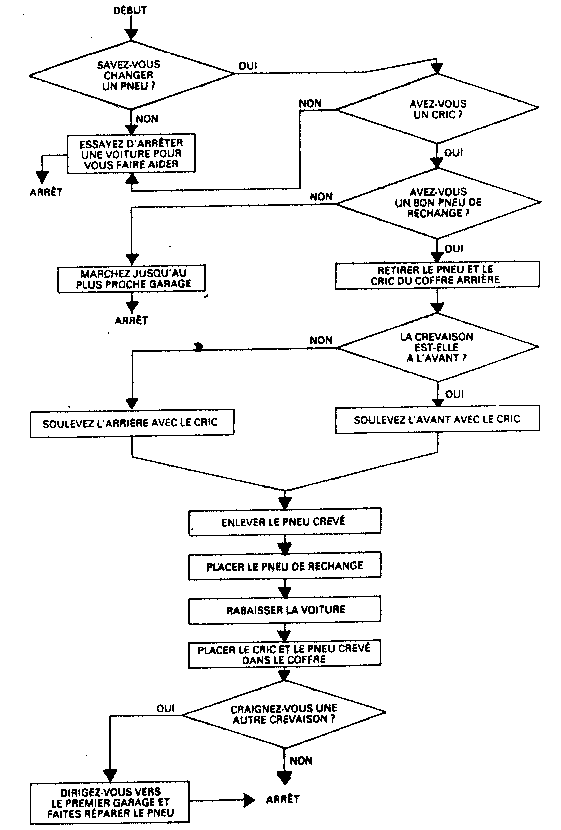
Le diagramme décrit l'enchainement chronoloqique des phases du programme. Les opérations arithmétiques, logiques et les entrées-sorties apparaissent dans des rectangles (ou autre figure géométrique) tandis que les branchements conditionnels, sortes d'aiguillages, sont figurés dans des losanges. L'exécution du programme ressemble alors a une promenade dans un labyrinthe, comportant une entrée, une sortie, différentes stations où il faut exécuter quelque chose, et des aiguillages dont la position dépend de l'état de certaines mémoires au moment où le programme vient à y passer.
De nombreux programmes de gestion écrits en COBOL obéissent au schéma suivant :
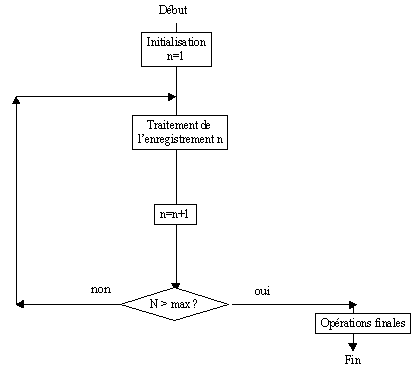
La transcription sur machine d'un programme préparé sous forme d'ordinogramme est relativement simple. Le passage d'un bloc d'instructions au suivant s'effectue selon le cas en séquence, par un branchement (GOTO inconditionnel) ou par un test (IF... THEN... ELSE... ). Ce mode de représentation présente toutefois des limites et, pour des algorithmes complexes, est assez différent des modes de raisonnement humain.
Il est possible de n'écrire la séquence en cause qu'une seule fois, à l'extérieur du programme, qui devient le programme principal, et d'y faire appel depuis ce dernier. On dit qu'on a créé un sous-programme.
Exemple :
| AVANT | APRES |
|---|---|
|
séquences identiques programme | 1 appe 1 S appel nappel 4 programme principal ler appel 2e appel 3e appel sous-programme |
CALL <nom du sous-programme> [(<X1>, <X2>, ... , <Xn>)]
| Xl = (-B + SQR (B * B - 4 * A * C))/(2 * A) |
Les variables entières permettent la représentation de nombres, positifs ou négatifs à l'intérieur d'un intervalle qui dépend dit nombre de bits utilisés, puisqu'un groupe de n bits ne peut prendre que 2n valeurs différentes.
Exemples de déclaration de variables entières :
| INTEGER N, SOMME | (FORTRAN, ALGOL) |
| DEFINT N,S | (BASIC) |
Exemples de déclaration de variables en virgule flottante
| REAL X, Y | (FORTRAN) |
| DEFSNG X,Y | (BASIC) |
Exemples de déclaration de variables en virgule flottante sur 64 bits
| DOUBLE PRECISION Z | (FORTRAN) |
| DEFDBL Z | (BASIC) |
Les variables logiques ne peuvent prendre que deux valeurs, "vrai" ou "faux", et ne nécessitent, en principe qu'un seul bit de mémoire pour être stockées.
Exemples de déclaration :
| LOGICAL B | (FORTRAN) |
| BOOLEAN B | (ALGOL) |
Plus récemment, les langages évolués ont permis une extension très utile en ouvrant la possibilité de représenter des chaÎnes de caractères pour des variables de texte :
| STRING CH | (FORTRAN) |
| TEXT CH | (SIMULA) |
| DEFSTR CH | (BASIC) |
Les mêmes identifieurs peuvent être utilisés pour décrire des sous-programmes
| PROCEDURE, FUNCTION | (ALGOL) |
| SUBROUTINE, FUNCTION | (FORTRAN) |
D'autres extensions ont été développées, telles que la désignation par un nom de variable de vecteurs ou de matrices de nombres, ou même de chaînes de caractères (APL, SUPERBASIC) ou des ensembles composites de données dénommés objets (SIMULA).
| X = 1 | (FORTRAN) |
| LET X = 1 | (BASIC) |
| X : = 1 | (ALGOL) |
| X ¬ 1 | (A.P.L.) |
L'expression située à droite du symbole d'affectation peut prendre des formes complexes par le jeu d'opérations arithmétiques, et d'imbrication de parenthèses.
Exemples :
| i = i + 1 | (FORTRAN) |
| N ¬ rV | (A.P.L.) |
| X := (2 + 2)/(3 * F) | (ALGOL) |
concaténation de chaînes :
| COUPLE = PAPA ! " ET " ! MAMAN | (L.S.E.) |
| A$ = B$ + C$ | (BASIC) |
Lorsqu'une expression met en jeu plusieurs opérateurs sans parenthèses, l'ordinateur exécute en premier lieu certaines opérations qu'il juge prioritaire. Par exemple, FORTRAN reconnaît :
X = A * 2 + 3
et l'exécute comme s'il lisait X = (A x 2) + 3 parce que l'opérateur "*" (multiplier) bénéficie d'une précédence sur "+" (addition).
Par contre, le langage A.P.L. ignore toute précédence et, en l'absence de parenthèses exécute les opérations de droite à gauche
X ¬ A * 2 + 3
est interprété comme X ¬ (A * (2 + 3)
| READ | (FORTRAN, ALGOL) |
Pour lire une donnée à partir d'un clavier, on utilise :
ACCEPT (FORTRAN) ou INPUT (BASIC) ou INKEY$ (BASIC)
Pour écrire une carte perforée ou une ligne d'imprimante, on utilise :
WRITE (FORTRAN) ou LPRINT (BASIC)
Pour afficher sur écran vidéo ou écrire sur support magnétique externe, on utilise :
WRITE (FORTRAN) ou PRINT et PRINT USING (BASIC)
Le saut inconditionnel est effectué systématiquement :
| GOTO | (FORTRAN, ALGOL, BASIC) |
| ® | (A.P.L.) |
Pour exécuter plusieurs fois une même séquence de programme, il existe des instructions d'itération :
| FOR i = i1 to i2 step i3 : <liste d'instructions> s NEXT | (BASIC) |
| DO <adresse> i = i1, i2, i3 ... | (FORTRAN) |
| FOR i =i1 to i2 step i3 DO <instruction> | (ALGOL) |
ALGOL et ses dérivés introduisent une notion de boucle, indéfinie ou conditionnelle
LOOP <instruction>
WHILE <condition> DO <instruction>
Le saut conditionnel utilise l'instruction IF
| FOR i = i1 to i2 step i3 : <liste d'instructions> : NEXT | (BASIC) |
| IF <condition> THEN <instruction> [ELSE <instruction>] | (ALGOL, BASIC) |
| IF <condition> <instructions> [.ELSE. <instruction>] | (SUPER FORTRAN) |
Enfin, le GOTO calculé permet de réaliser un aiguillage multiple, en sélectionnant une adresse de branchement à l'intérieur d'une liste en fonction d'un argument entier compris entre 1 et n.
| ON <expression> GOTO L1, L2, ... Ln | (BASIC) |
| GOTO (L1, L2 , ... Ln ), <expression> | (FORTRAN) |
L'appel de sous-programmes est un saut de type particulier vers une autre adresse du programme qui se caractérise par un retour à l'instruction qui suit immédiatement l'appel à la fin de l'exécution du sous-programme.
| GOSUB adresse | (BASIC) |
| CALL nom de sous-programme | (FORTRAN) |
La fin d'un sous-programme se définit par l'instruction particulière
RETURN (FORTRAN, BASIC)
La société IBM a popularisé les sigles suivants :
| OS (operating system) | moniteur des premières machines de puissance, qui traitaient l'un après l'autre les programmes par lots (batch processing) rangés dans une file d'attente, sous forme de cartes perforées ou de bandes magnétiques |
| DOS (disk operating system) | moniteur des machines équipés de vastes mémoires auxiliaires à disques, sur lesquels sont rangée l'ensemble des programmes et leurs données. |
| TSS (time-sharing system) | moniteur des machines capables de dialoguer simultanément avec plusieurs utilisateurs en ligne, entre lesquels il faut gérer et répartir le temps de calcul laissé disponible après prélèvement du temps nécessaire en système d'exploitation pour se gérer lui-même. |
Sur les micro-ordinateurs, après une période d'anarchie, le même type de besoin est apparu, et s'est finalement résolu, par sélection naturelle, par la généralisation du système d'exploitation dénommé CP/M.
CPM fut développé au départ par un brillant concepteur de logiciels pour son utilisation personnelle : Gary Kildalm, le fondateur de Digital Research, qui distribue aujourd'hui CP/M et d'autres produits logiciels. En 1974, disposant des premières unités de disques souples et ne possédant aucun système d'exploitation pour ce dernier, Gary Kildalm décida de créer sa propre version d'un système d'exploitation minimal qui lui fournisse également des facilités raisonnables de gestion de fichiers. La première utilisation commerciale de ce produit, dénommé CP/M, intervint à grande échelle sur les ordinateurs IMSAI aujourd'hui disparus.
De manière traditionnelle, les systèmes d'exploitation ont toujours coÛté des millions de dollars pour leur développement et se sont toujours vendus à un prix très élevé. Gary Kildalm eut la vision d'un système d'exploitation simple, vendu à très bon marché et mis à la disposition de tous les utilisateurs de petits ordinateurs.
Vendu à 100 dollars, ce système a été largement diffusé et s'est imposé de fait comme standard pour tous les systèmes d'exploitation sur microprocesseurs à 8 bits.
Pour satisfaire les besoins des utilisateurs de machines e temps partagé, une nouvelle version a été créée sous le nom de MP/M (multiprogramming Control Program for Microprocessors).
Grâce à CP/M et MP/M, et en dehors de la volonté des constructeurs de micro-ordinateurs, le marché des logiciels correspondants s'est trouvé considérablement élargi et banalisé puisque les programmes élaborés sur l'une de ces machines sous CP/M ou MP/M sont devenus transposables sur n'importe quelle autre.
(N.B. : les auteurs de programmes en BASIC et APL ne sont guère favorisés de ce point de vue)
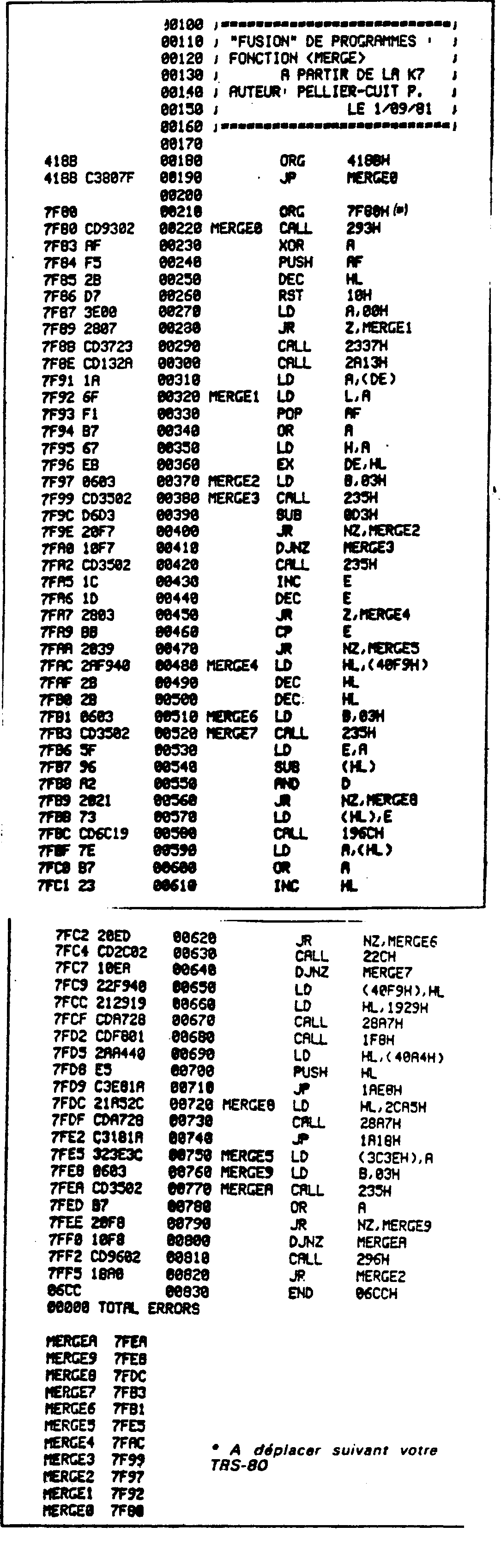
Les TRUCS du TRS-80Fusion de programmes BASICS à partir de la cassette et en utilisant "merge" Utilité (à chaque jour suffit sa peine) : grâce à ce programme, vous pourrez édifier des programmes en BASIC morceau par morceau : vous faites un sous-programme, un second... qui seront les sous-ensembles du logiciel final. Une fois que ces sous-programmes fonctionnent, vous les fusionnez en un grand programme. Mode d'emploi : après avoir chargé un logiciel par voie normale, entrer la commande: MERGE " NOM DU PROGRAMME ". Le nom du programme est facultatif : l'ordinateur prend le premier qu'il trouve, sinon il recherche celui que vous désirez sur la cassette. Marcel Pellier-Cuit |
|
Les Babyloniens utilisaient une valeur approchée p=3, Les Egyptiens se fiaient à l'expression p = 4 (8/9)2 = 3,16048 (Creative Computing)
Le nombre p a toujours excité l'imagination des hommes.
Il y a environ 2 000 ans, les Babyloniens utilisaient déjà la valeur approchée p = 3. tandis que les Egyptiens se fiaient à l'expression p = 4 (8/9)2 = 3,1604928
C'est ce que nous apprend CREATIVE COMPUTING qui présente dans son numéro de mai 1980 une intéressante étude sur es vicissitudes du nombre p à travers les âges et sur les différents algorithmes utilisés pour sa génération. Les temps modernes ont évidemment mis les ordinateurs à contribution et la revue cite un certain nombre de résultats obtenus depuis l'ENIAC (plus de 2000 décimales, en 1949), jusqu'au CDC 6600 (environ 500 000 décimales, en 1967). L'article fait état de plusieurs méthodes de calcul, le plus souvent basées sur les séries et tout à fait adaptées à l'emploi des calculateurs électroniques.
Une méthode consiste à calculer p par la très élégante formule:
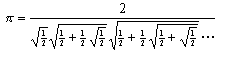
Traitée en BASIC, cette formule donnerait lieu à l'écriture d'un programme comme celui de la figure A.
Une méthode plus courante revient à estimer p à l'aide au périmètre d'un polygone inscrit dont le nombre de côtés tend vers l'infini.
Traitée en APL cette méthode déboucherait sur le programme représenté à la figure B.
Néanmoins, précisons tout de même que CREATIVE COMPUTING ne mentionne pas une méthode amusante (peu recommandée, toutefois, si on recherche la précision), fondée sur le célèbre problème de l'aiguille de Buffon. On trace sur une feuille de papier disposée horizontalement une série de droites parallèles et équidistantes (distance d). On jette sur cette feuille de papier une aiguille de longueur 10 < d pour fixer les idées). On démontre assez simplement que la probabilité pour que cette aiguille coupe une quelconque des lignes tracées sur la feuille de papier est
Il est donc possible d'estimer p à partir d'une série d'épreuves aléatoires
où f est la fréquence observée de l'événement rencontre de l'aiguille avec une ligne et p un estimateur de p. A titre d'exemple, une expérience portant sur 100 épreuves (c'est évidemment bien insuffisant) a donné ici la valeur p = 3,06. Cette approche est réalisable par programme, (en langage APL, par exemple, qui dispose d'une fonction de génération de nombres au hasard), selon la méthode de Monte-Carlo.
Ce genre d'application présente un intérêt sans doute plus théorique que pratique. Mais sa valeur pédagogique est indéniable.
|
Fig. A. - Programme basic de calcul de p
|
Fig. B. - Calcul de p en APL
|
|
fig.4. Programme calculant la moyenne d'un enstntble de nombres en BASIC, FORTRAN et APL. Le programme en APL utilise 10 caractères.
1 CHAINE LU,CAR,STACK
2 TABLEAU PILE(20)
3 AFFICHER 'MACHINE A CALCULER'
4 AFFICHER 'ENTREZ UNE FORMULE:'; LIRE LU; SI LU='' ALORS TERMINER
5 AFFICHER('=',U,/]&CALC(LU,4); ALLER EN 4
6
7 PROCEDURE &CALC(EXPR,REJET)LOCAL EXPR,REJET,TOP; CHAINE EXPR,TOP
8 K¬0; STACK¬'('; CAR¬&SCAN(EXPR)
9 SI CAR='(' ALORS DEBUT STACK¬CAR!STACK; CAR¬&SCANC(EXPR); ALLER EN 9 FIN
10 SI CAR>='O' ET CAR<='9' ALORS DEBUT &PUSH(&INR(EXPR)); ALLER EN 12 FIN
11 &ERR('CARACTERE ILLEGAL: '!CAR); ALLER EN 26
12 SI CAR=')' ALORS ALLER EN 19
13 SI CAR='*' OU CAR='/' ALORS ALLER EN 16
14 SI CAR='+' OU CAR='-' ALORS ALLER EN 17
15 ALLER EN 22
16 TOP¬&LEFT(STACK,1); SI TOP='*' OU TOP='/' ALORS &PULL(); ALLER EN 18
17 TOP¬&LEFT(STACK,1); SI TOP#'('ALORS DEBUT &PULL(); ALLER EN 17 FIN
18 STACK¬CAR!STACK; CAR¬&SCAN(EXPR); ALLER EN 9
19 SI STACK='(' ALORS DEBUT &ERR(') DE TROP'); ALLER EN 26 FIN
20 TOP¬&LEFT(STACK,1); SI TOP#'('ALORS DEBUT &PULL(); ALLER EN 19 FIN
21 STACK¬SCH(STACK,2,''); CAR¬&SCAN(EXPR); ALLER EN 12
22 TOP¬&LEFT(STACK,1); SI TOP#'(' ALORS DEBUT &PULL(); ALLER EN 22 FIN
23 SI STACK#'(' ALORS DEBUT &ERR('( DE TROP'); ALLER EN 26 FIN
24 SI CAR#'' ALORS DEBUT &ERR('CARACTERE ILLEGAL:'!CAR); ALLER EN 26 FIN
25 RESULTAT PILE(1)
26 RETOUR EN REJET
27
28 PROCEDURE &PULL()LOCAL C; CHAINE C; C¬&SCAN(STACK)
29 SI C='+' ALORS DEBUT PILE(K-1)¬PILE(K-1)+PILE(K); ALLER EN 34 FIN
30 SI C='-' ALORS DEBUT PILE(K-1)¬PILE(K-I)-PILE(K); ALLER EN 34 FIN
31 SI C='*' ALORS DEBUT PILE(K-1)¬PILE(K-I)*PILE(K); ALLER EN 34 FIN
32 SI C='/' ALORS DEBUT PILE(K-1)¬PILE(K-I)/PILE(K); ALLER EN 34 FIN
33 &ERR('CARACTERE ILLEGAL: '!C)
34 K¬K-1;RETOUR
35
36 PROCEDURE &PUSH(X) LOCAL X; K¬K+l; PILE(K)¬X; RETOUR
37
38 PROCEDURE &ERR(S); CHAINE S; AFFICHER[/,'ERREUR: ',U,/]S ; RETOUR
30
40 PROCEDURE &INR(EXPR) LOCAL K,INR; CHAINE EXPR,INR; INR¬''; K¬0
41 INR¬INR!CAR; CAR¬&SCAN(EXPR); SI CAR>='0' ET CAR<='9' ALORS ALLER EN 41
42 SI CAR='.' ALORS DEBUT K¬K+1; Sl K<2 ALORS ALLER EN 41 FIN
43 RESULTAT CNB(INR,1)
44
45 PROCEDURE &SCAN(E)LOCAL C;CHAINE E,C; C¬&LEFT(E,1)
46 E¬SCH(E,2,''); RESULTAT SI C=' ' ALORS &SCAN(E) SINON C
47
48 PROCEDURE &LEFT(E,N); CHAINE E; RESULTAT SCH(E,1,N)
|